TradingAgents: Multi‑Agents LLM Financial Trading Framework
I recently came across a paper circulating on X: “TradingAgents: Multi‑Agents LLM Financial Trading Framework”. At first glance, it’s exciting. Multi‑agent systems, large language models, finance – all the right buzzwords. I wanted it to be good. Get the 38-page paper: https://arxiv.org/pdf/2412.20138
But after reading the paper more carefully, my excitement quickly turned into skepticism.
This post explains why backtesting LLM‑based trading agents is fundamentally problematic, and why most results you see today should be treated with extreme caution.
see the post on X
The Core Problem: You Cannot Backtest an Omniscient Model
LLMs are not classical models trained on a fixed dataset.
They are trained on massive, unstructured corpora that almost certainly include:
- Financial news
- Market commentary
- Post‑hoc analysis
- Earnings summaries
- Macro narratives
- Social media discussions
If the model was trained after the end date of your backtest, then your backtest is contaminated by future information – even if the model is not explicitly fed price data.
This is not a minor issue. It’s a hard violation of the no‑lookahead assumption that makes any quantitative evaluation meaningless.
In short:
If your model has read the future, your backtest is dead.
“But the Model Only Sees Past Prices” – That’s Not the Point
A common defense is:
“We only provide historical prices and indicators to the LLM.”
This completely misses the issue.
The LLM already knows:
- How 2022 inflation played out
- How markets reacted to rate hikes
- Which narratives worked or failed
- Which assets collapsed or outperformed
Even if you only show it prices from 2021, the latent representations are shaped by post‑2021 outcomes.
This is information leakage at the model level, not the dataset level – and it cannot be fixed with standard backtesting hygiene.
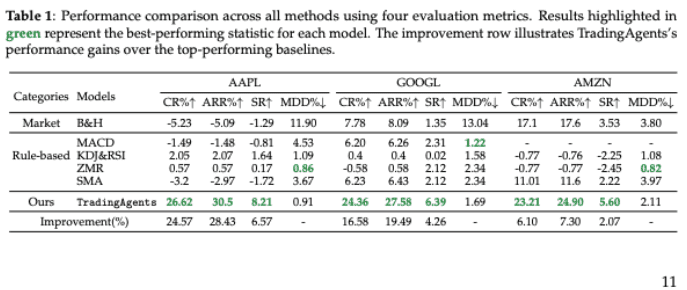
The “Backtest” Window Is a Red Flag
In the paper, the reported backtest period is:
January 1st, 2024 – March 29th, 2024
That’s roughly 3 months.
This is not a backtest. It’s a demo.
A window this short:
- Cannot cover different regimes
- Cannot reveal drawdown behavior
- Cannot estimate tail risk
- Is extremely sensitive to randomness
In quantitative finance, this would never pass even the lowest bar of validation.
Why This Is Not Just “Overfitting”
This is worse than classical overfitting.
With standard models:
- You can freeze data
- You can control features
- You can do proper walk‑forward validation
With LLMs:
- You do not control the training corpus
- You do not know what market narratives were absorbed
- You cannot “untrain” future knowledge
This makes historical evaluation structurally ill‑posed.
What Would Be Required for a Legitimate Test?
To even begin taking such results seriously, you would need:
- A model trained strictly before the test period
(not fine‑tuned – trained) - A frozen inference environment
No updates, no API drift, no prompt changes - A long out‑of‑sample window
Multiple years, multiple regimes - Transaction costs, slippage, latency
Explicitly modeled, not hand‑waved - Clear failure cases
Where and why the agent loses money
Today, almost no LLM‑trading paper meets these criteria.
What LLMs Might Actually Be Good For
To be clear: this is not an anti‑LLM rant.
LLMs can be useful in trading – just not in the way these papers claim.
Promising use cases include:
- Feature generation (text → structured signals)
- Regime classification assistance
- Research tooling and hypothesis generation
- Automation around execution, reporting, monitoring
But alpha generation via backtested LLM agents?
We are nowhere near that.
Bottom Line
LLM trading backtests today suffer from a fatal flaw:
You cannot test the past with a model that has already read the future.
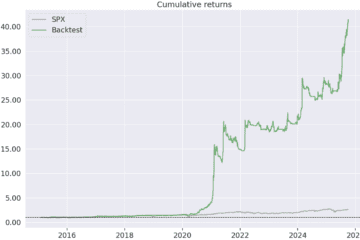
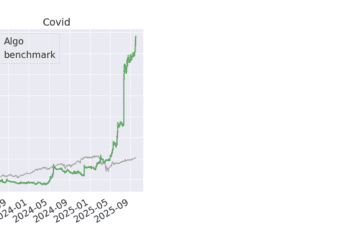
Until this is addressed seriously – not with 3‑month demos and glossy charts – most results should be treated as research theater, not quantitative evidence.
If you’re building real systems with real money, skepticism is not optional. It’s a requirement.
0 Comments